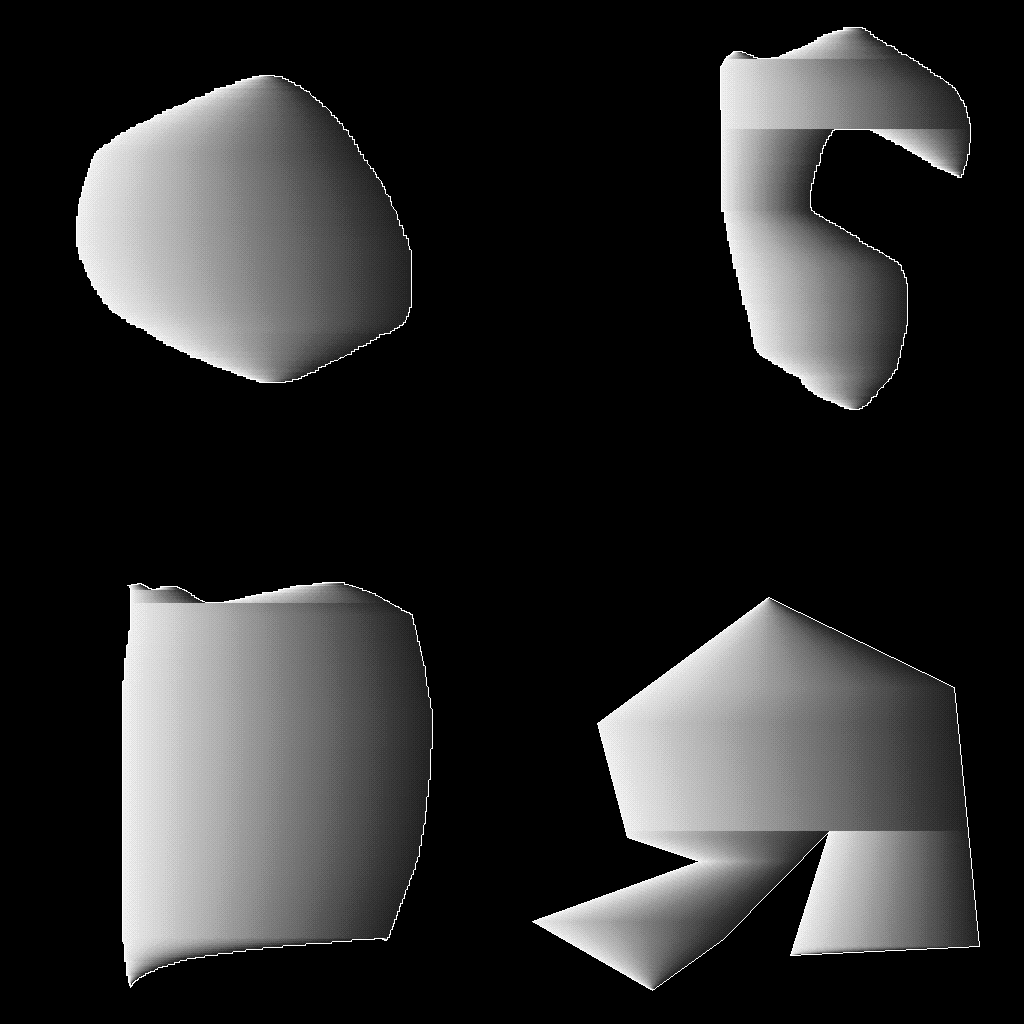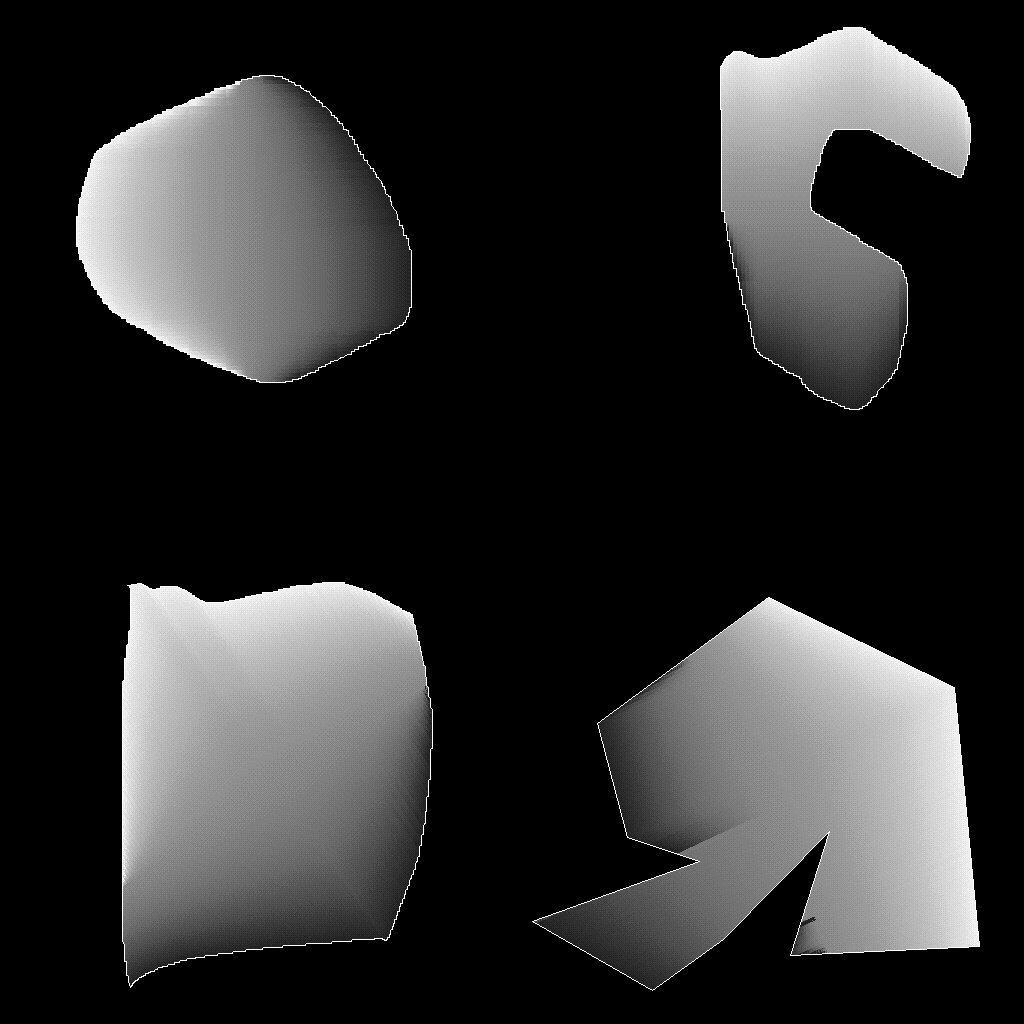I've been spending the last year working (off-and-on) on some changes
to Grafx2!
Grafx2, for anyone not aware of it, is an old piece of pixel art
software from the 90s, for doing 256 color art. It closely mimics
Deluxe Paint, for those familiar with it.
There are a few weird aspects of the UI (attributable to the fact that
it's from the 90s), but the biggest issue I have with it is the
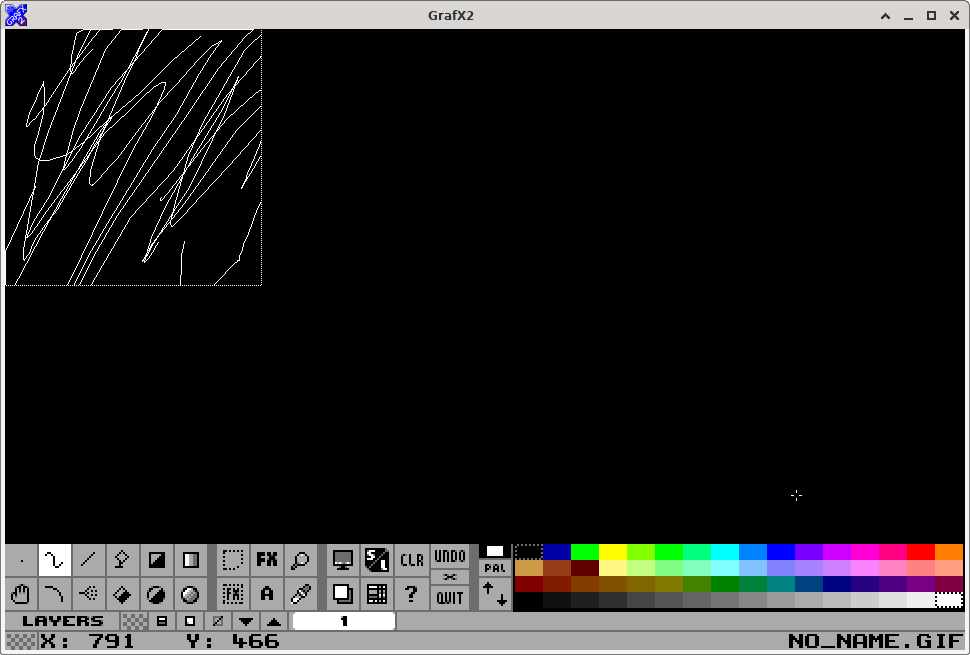
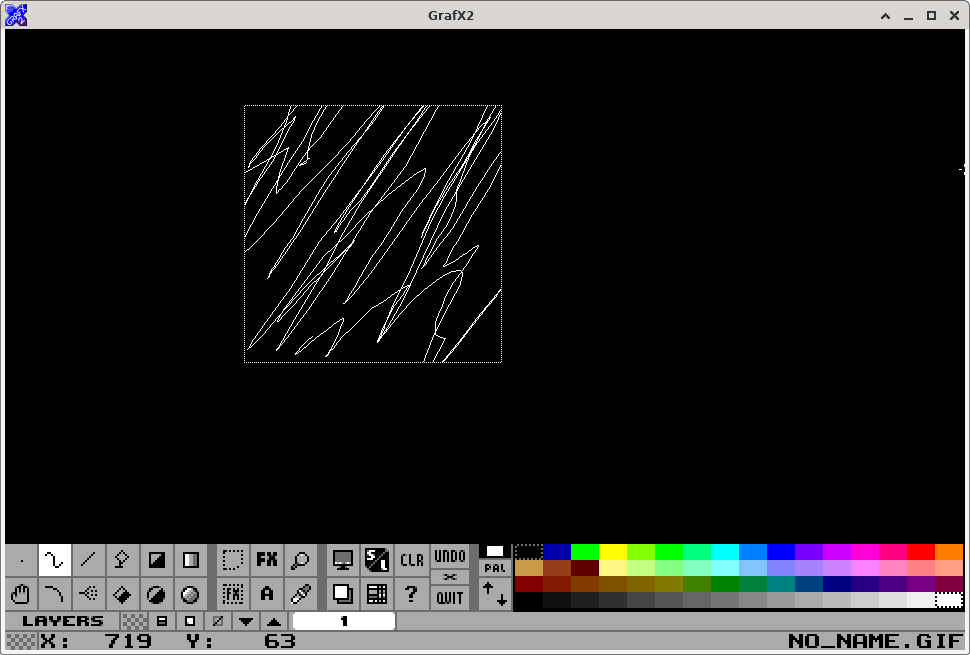
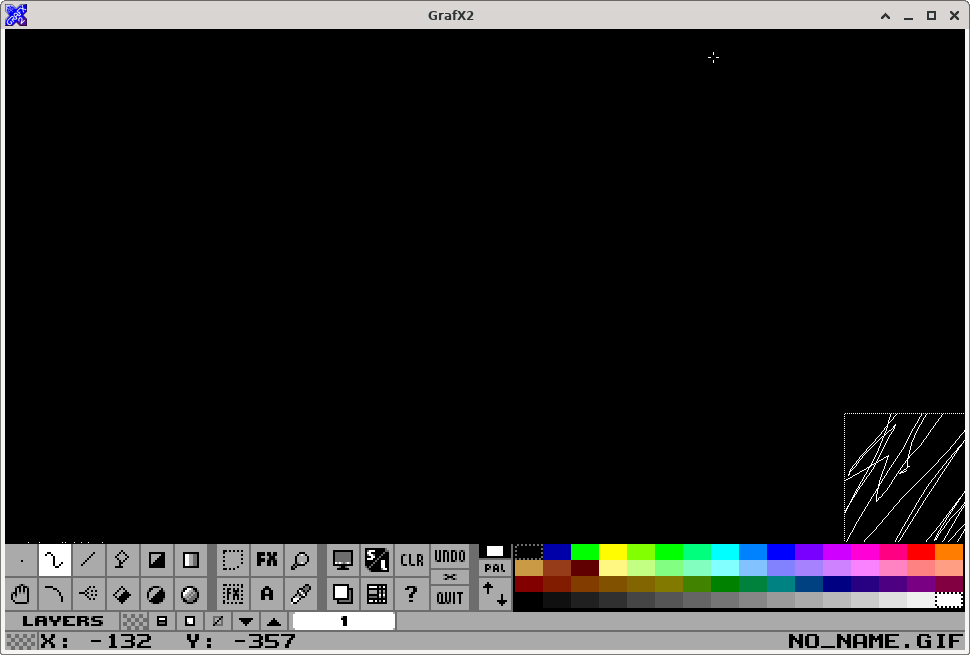
limited ability to pan around the image. As of this writing, Grafx2
doesn't let you move the visible area in a way that would let you
center the upper-left corner of the image. You can't pan further to
the left than the point where the left edge touches the left side of
the screen (or window). Similarly for the top edge and vertical
panning.
Thankfully, Grafx2 is also open-source! So I figured "oh! Why don't I
just go in and fix that?"
The result was a lot more work than I bargained for. But it's
finally starting to show results. You can now pan the image around a
lot more freely in Grafx2!
I have a branch that, while the code is SUPER MESSY and spills out a
ton of warnings, it's still functional. Almost everything works
(except one of the many pixel scaling modes, as of this writing).
Many tools had their own (redundant) clipping implementation, so a
lot of that has been shifted out into some common clipping
functions.
A lot of the existing global variables that describe the
usable/visible area have been swapped out with more descriptive
names, with dedicated clip area structures.
Many variables throughout the application needed to be converted
into signed types.
Every single pixel scaling mode has separate redundant code that
needed an update. The redundancy here would be difficult to factor
out, because a lot of these functions - being low-level blitters and
such - need to avoid any extra function call overhead.
Remaining work
The code is extremely messy at the moment, and needs a ton of
cleanup, but everything is currently working. At least, on PC.
It still needs testing on all the other platforms Grafx2 runs on. This
is largely due to switching around some integer data types that might
end up with different sizes or signedness on other platforms with
different data models.
So I watched Mark Ferrari's entire GDC talk "8 Bit & '8 Bitish'
Graphics-Outside the
Box". It's a fantastic
talk by one of the greatest pixel artists alive today. He talks about
a lot of his work, and spends a section of the video going into some
details about his techniques.
I tried to follow along as best I could in his tutorial sections using
Grafx2. Unfortunately, there are a few
things that Deluxe Paint and/or Pro Motion can do that Grafx2 still
can't. One of those things I'd really like to use is Deluxe Paint's
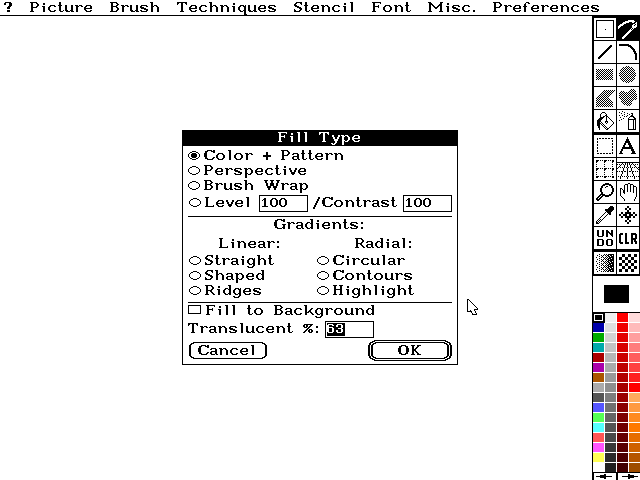
gradient fill modes.
So I've been trying to dissect the way Deluxe Paint does its
shape-conforming gradient fills, and seeing if I can implement them
myself in Grafx2. (Grafx2 also a has an existing feature request that
mentions this functionality: Add more flexible
gradients)
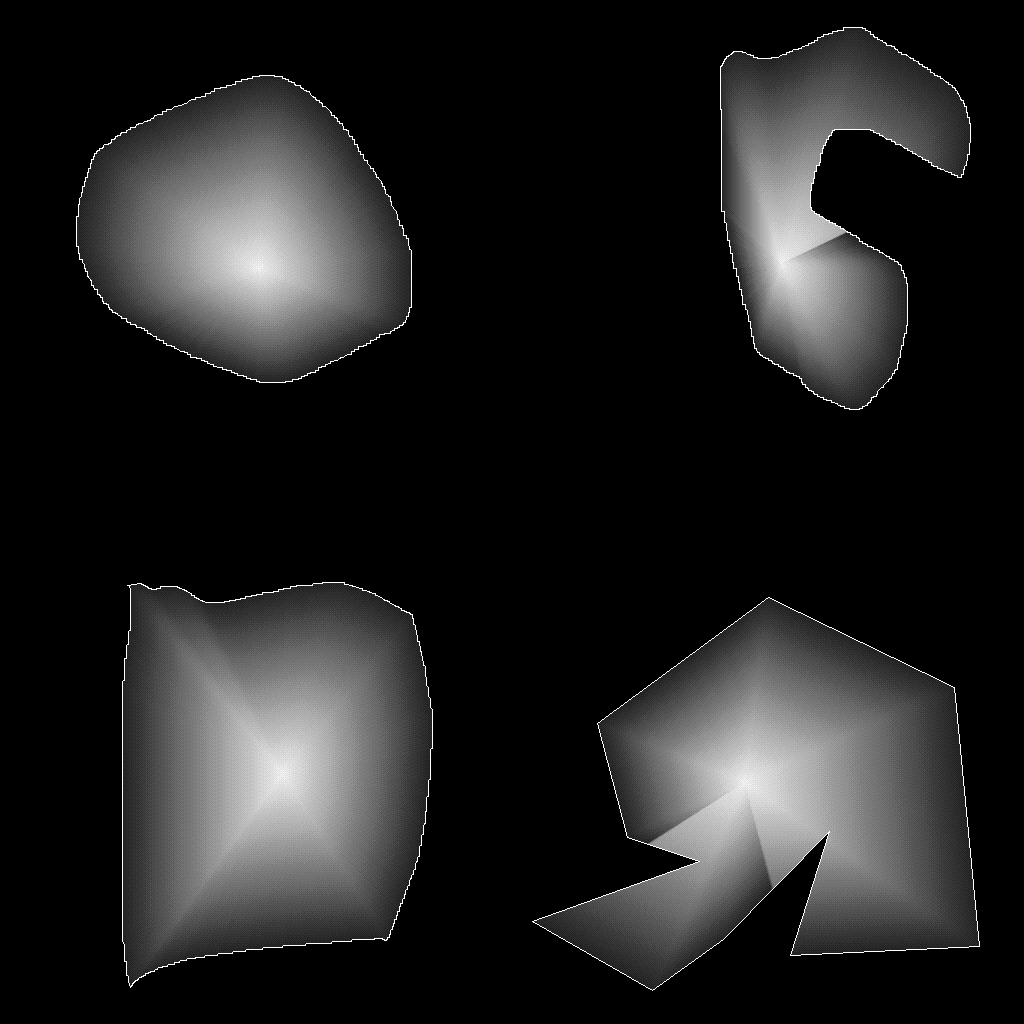
Here's what I'm up against:
Findings
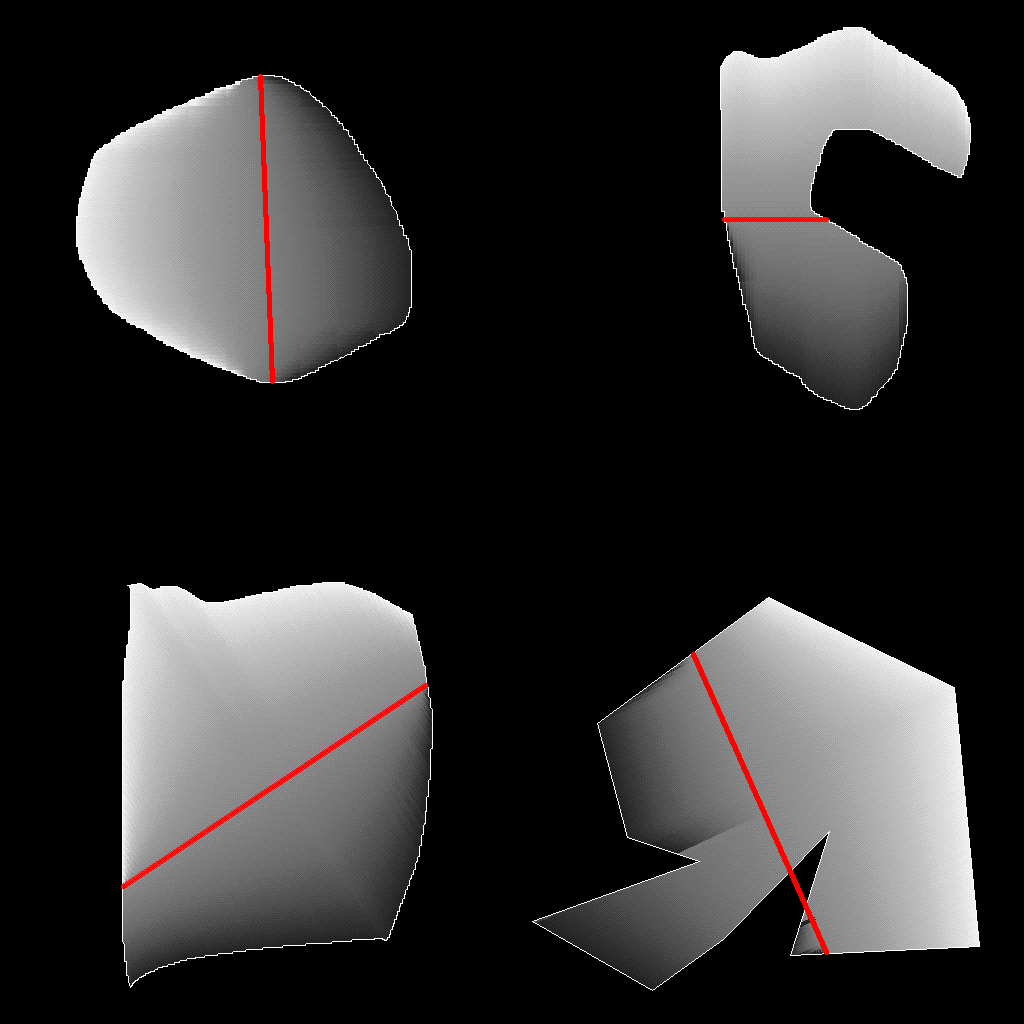
"Contour" fill
A centerpoint is selected by the user.
For every point to be filled:
Find a the point along the edge that's the furthest away from
the center point, where the point to be filled lies in between
it and the center point.
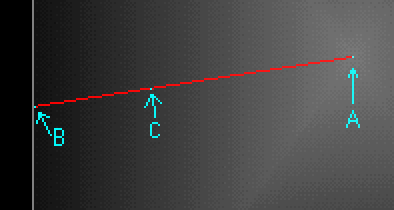
Where A is a vector for the the centerpoint,
B is the edge point, and C is the point
to be filled.
The point along the gradient to use, t, is in the range of 0
through 1, and calculated as... t = ||C - A|| /
||B - A||
This is just an inverse-lerp. We want to see how far along the line
between A and B we are, and that determines where along the
gradient we are.
The key here to replicating some of DP's odd behavior is that it's
always using the most distant edge. This is why DP's fills look a
little weird when the fill wraps around curves (where it has multiple
edges to choose from along some lines coming from the center.
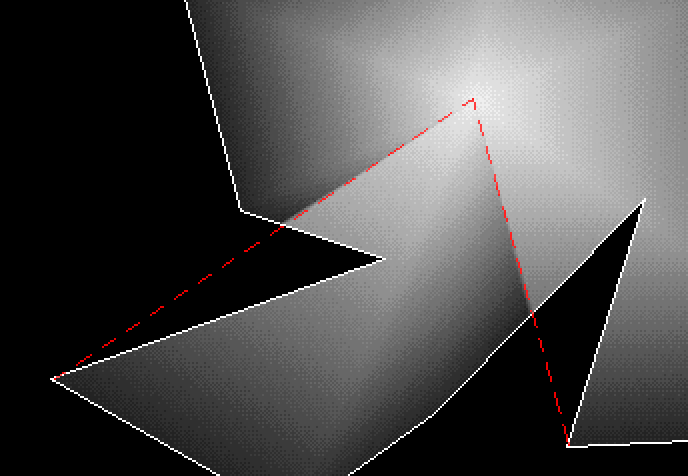
From our top-right example, we can see how this breaks down. The
gradient is being done based on the most distant edge, so it's
affected by the hook shape.
And the bottom-right example. We can clearly see where it's preferring
far edges to interpolate to.
"Highlight" fill
I believe this is identical to "Countour", but with a different
mapping to the actual gradient. t may be affected by a curve,
similar to a gamma curve. So I'm not going to cover this one here.
"Ridges" fill
For every pixel...
find the nearest edges on the left and right (straight
left/right).
Do the inverse lerp described in the "Contour" fill. A is the
nearest left edge, B is the nearest right edge, and C is
the point being filled.
This one also looks weird when it goes around corners.
"Linear" fill
This is a pretty basic linear gradient fill. Grafx2 already supports
this, so it's only here for completeness.
Pick a center point (A) and an offset (B).
For every point to be filled:
Project that point onto the vector A - B, to make
point C.
Do an inverted lerp with A, B, and C as above.
"Circular" fill
This is a basic radial gradient. Grafx2 already does this, too, so we
won't get into it.
"Shape" fill
This one is like the "contour" fill, except that it uses a line
instead of a single centerpoint. We'll do the same math as before, but
with an extra projection. Rather than a single mid-point, as used in
the "contour" mode, we need to use an entire line.
It'll work exactly the same as the contour gradient, except that we
need to find the closest point along a given center line, and use that
as the A vector in the equation.
Results
So far I've only worked on figuring out the "contour" fill mode. My
results are looking pretty promising, though! Here's what my prototype
spits out with the same image input (slightly different points
selected as centers):
It doesn't match the DP results exactly, but that's more a matter of
correctly mapping the gradient to color values than anything to do
with the technique.
Next update will probably focus on the "shaped" mode and
optimizations.
So quite a while ago I started building a scripting language and, over
the course of about a year, actually finished it (for some definitions
of "finished"). The scripting language was named "Ninkasi", after the
Sumerian beer goddess.
Years later, as part of a job interview, the company I was applying to
wanted me to do a presentation to the programming team. The
presentation could be whatever I wanted it to be, so I picked the one
thing I'm more familiar with than anyone else, more complex than most
stuff I've worked on, has well-defined goals, and is a project that I
actually finished, and that was my scripting language.
I've gone ahead and transcribed the slides I made from that
presentation here, for anyone interested in the inner workings or
development of it.
It's a project I'm still damn proud of, even if there are a few things
I'd do differently if I did it again, and I cover those things near
the end of the presentation.
Original slides are available here, created on Aug 8th, 2020: Google
Slides
deck.
(Going forward, any updates are going to happen on this article, so
the slides may be outdated.)
The scripting language source itself is available here:
Lua doesn't have it. Some things indexed by pointer.
Floating-point determinism only cared about as far as running on
the same platform.
Should run the exact same on every platform, aside from that
floating point determinism.
Verified in testing by hashing the entire VM state and comparing
serialized state snapshots
6. Features I wanted, last one
External object lifetime management.
Fire off callbacks when external object handle is GCed. (Can do
in Lua through metatables, but as a result sandboxing involves
removing metatable manipulation.)
Hosting application can hold external handles to internal VM
objects. (Can do in Lua with gross registry tricks.)
7. Okay I lied. This is the most important one
FOR FUNSIES.
BECAUSE I CAN AND NOBODY CAN STOP ME.
8. Other cool stuff
Wasn’t part of the original reasoning but I like it anyway!
9. Cool stuff
C-like syntax.
Maybe unintentionally closer to Javascript.
No dependencies beyond C standard lib.
Might even be able to run without that with some tweaks.
Coroutines!
Added late in development because I missed having it in Lua.
Written entirely in C89.
Except for // comments everywhere.
Compiles in C++ mode, too.
10. Cool stuff (cont.)
Runs in DOS in real-mode and 32-bit protected mode, up through
modern platforms like 64-bit Linux.
DOS version compiled on Watcom 10.0a from 1994.
Other compilers might need some minor work in nktypes.h to
figure out object sizes through preprocessor. (int32_t not in
C89, int in real-mode = 16-bit, int in 32-bit mode = 32-bit,
etc).
VM state snapshots are binary compatible with VM running on other
platforms.
Not cross-endian compatible, could be with some work.
11. Cool stuff (cont.)
Handles malloc() failures.
Will get into this later.
12. Example code
What the heck does this thing even look like?
13. C API Example
This is an extremely simple program that creates a VM, hooks up an
output function, compiles a one-line hard-coded script, executes it,
and cleans up. Error reporting is minimal.
#include "nkx.h"
#include <stdio.h>
#include <assert.h>
// "print" function callback.
void printFunc(struct NKVMFunctionCallbackData *data)
{
nkuint32_t i;
for(i = 0; i < data->argumentCount; i++) {
printf("%s", nkxValueToString(data->vm, &data->arguments[i]));
}
}
int main(int argc, char *argv[])
{
// Create the VM.
struct NKVM *vm = nkxVmCreate();
// Create a compiler so we can compile new code. (Loading binary
// state snapshots doesn't need this.)
struct NKCompilerState *compiler = nkxCompilerCreate(vm);
// The most basic function we will need is "print". Otherwise it's
// not possible to get anything out. (Well, it is. You just have
// to have the hosting application explicitly pull data out of the
// finished VM.)
nkxVmSetupExternalFunction(
vm, compiler,
"print", // Used as as internal name for matching up during
// deserialization AND as a variable name so the
// script can call it.
printFunc, // The function itself.
nktrue, // True to add this as a global variable (otherwise
// there is no way to call it right away).
NK_INVALID_VALUE // Everything else is optional argument type
// and argument count checking.
);
// Compile the script. (You would do this multiple times before
// finalizing for multi-file scripts, or use a preprocessor to
// make it all go in as a single string.)
const char *scriptText = "print(\"foobar\\n\");\n";
nkxCompilerCompileScript(
compiler,
scriptText,
"internal" // Source file name (for error reporting).
);
// Done adding source files to compile. Write the end and finish
// setting up exported data.
nkxCompilerFinalize(compiler);
// TODO: Error check the compiler output for real (and display
// error messages if needed).
assert(!nkxVmHasErrors(vm));
// Run the program. (There are other ways to trigger execution,
// but this is the simplest.)
nkxVmExecuteProgram(vm);
// TODO: Error check execution.
assert(!nkxVmHasErrors(vm));
// Clean up and return success.
nkxVmDelete(vm);
return 0;
}
14. Ninkasi Code Example
Here's a simple example of Ninkasi script code. It generates a
Mandelbrot pattern (using numbers instead of colors), and prints it to
the console.
For this script to work, it would need a "print" function created,
just like above in the C API example. ("print" is not a build-in
function.)
// Mandelbrot generator demo for Ninkasi
for(var y = -1.0; y < 1.0; y = y + 0.05) {
for(var x = -2.0; x < 1.0; x = x + 0.03) {
var u = 0.0;
var v = 0.0;
var u2 = u * u;
var v2 = v * v;
var k;
for(k = 1; k < 100 && u2 + v2 < 4.0; ++k) {
v = 2.0 * u * v + y;
u = u2 - v2 + x;
u2 = u * u;
v2 = v * v;
}
if(k < 40) {
print(k % 10);
} else {
print(".");
}
}
print("\n");
}
15. The language itself
16. Types
integers
We use this (1 and 0) for booleans, too.
floats
strings
Immutable.
ID into string table.
functions
ID into function table.
arg count + start index.
Optional external function ID (for C callbacks).
"objects"
ID into object table.
Analogous to Lua tables.
foo.bar and foo["bar"] are the same.
Can be external references with type info.
Coroutines are treated as one of these.
nil
Just nil.
17. Syntax
Syntax is C-like.
Comments:
// This is a comment.
Variable declarations:
var thisIsAVariable;
var thisIsAVariableWithAValue = 1234;
if/else:
if(expression) statement;
if(expression) { statement; } else { statement; }
18. Syntaxes
while/for/do while:
while(expression) statement;
for(x = 0; x < 20; ++x) print(x, "\n");
do { statement; } while(condition);
Variable declaration supported in for loop. Scope is limited to loop.
for(var x = 0; x < 20; ++x) print(x, "\n");
Function declarations:
function functionName(arg1, arg2) { return arg1 + arg2; }
Note: Not a closure. Doesn't capture any variables.
Function calls:
functionName(1, 2);
Object creation/manipulation:
var thing = object();
thing["foo"] = "bar";
thing.foo = "bar";
20. Syntax: Resurrection
Coroutines:
// This is the function that the coroutine will execute.
function functionToCall()
{
print("Hello\n");
// Yield control back to the parent context.
yield();
print("there!\n");
}
// Create the coroutine object.
var coroutineObject = coroutine(functionToCall);
// Run it.
print("1... ");
resume(coroutineObject);
print("2... ");
resume(coroutineObject);
Output:
1... Hello
2... there!
21. Error handling
What to do when everything explodes so you don’t HCF for real.
22. “Normal” runtime/compile errors
Error report recorded as a string.
Theoretically possible to clear the stack, reset IP to program
start, and restart. Not recommended, though.
Leaves VM object itself in a "valid" state (objects can be
destroyed/cleaned up normally).
Program itself is probably not in a valid state (remnants left on
stack, half-completed instructions).
23. malloc() failure handling
Almost every nkx function starts with a setjmp.
Allocation failures cause a longjmp to the most recent setjmp.
Internal allocations are tracked so they can be freed without having
to actually unwind the stack.
Never longjmps past application code, if used correctly.
24. malloc() failure is considered a "catastrophic error"
VM will refuse to attempt more allocations.
VM state cannot be serialized. (Can with normal errors.)
Possible lurking NULL pointers left in VM.
NO DANGLING POINTERS.
Can still be cleaned up, but needs care, especially with respect to external objects.
External object tables/state MUST BE VALID because we don't really own those objects and can't clean them up ourselves.
25. Multi-module compilation
Or how I learned to stop worrying and wrote a C89 preprocessor from
scratch.
26. I wrote a C89 preprocessor from scratch.
Does that count as multi-module compilation? It should count. I’m
counting it.
Didn't use setjmp/longjmp for malloc() failure handling like Ninkasi itself.
Literally just checked every malloc().
Debatable as to which approach is less gross.
Sometimes "goto" is okay.
Used to be religiously against goto in C.
Every use of goto in nkpp is super clear.
Verbose names on your labels.
Very limited uses!
Pretty much just for cleanup to jump to the end of a function
where all the temporary data teardown happens.
28. Bytecode
There’s no assembler so if you want to go lower-level you get to do it
the hard fun way.
29. 42 instructions
1 no-op
6 basic arithmetic (+,-,*,/,-,%)
5 "push literal value onto stack" (int/float/str/func/nil)
4 misc stack manipulation (pop,pop#,peek,poke)
2 static space manipulation (peek,poke)
4 jumps and branches (jmp,jz,call,ret)
1 "end"
10 comparison and expression logic (>,<,>=,<=,==,!=,===,!,&&,||)
4 "object" related (create/set/get/len)
2 that are gross and should be removed soon related to an
anti-feature I never should have done.
3 coroutine (create/yield/resume)
30. Memory
All instructions address either the stack, a space in the static
address space, or a field on an object.
Objects are the closest equivalent to a heap it has.
No other registers.
31. Serialized binary format
Contains the entire state of the VM.
Includes even things like...
the bytecodes themself.
what errors have been thrown.
garbage collector state.
external data owned by hosting application that it decides to
serialize with external objects.
file/line markers for debugging.
exported function/variable names.
A “compiled” Ninkasi script (.nkb) is a serialized state that was
saved after compilation but before execution.
32. Difficult Fun bugs found during development
33. Real-mode DOS specific stuff
In the “Huge” memory model with the 1MB address space, size_t is
still 16-bits.
Internally Ninkasi used 32-bit for everything. 32-bit allocation
of > 65535 bytes got truncated. Worse yet, test was a string
copy. Allocation was truncated but copy was not, so it just
filled the next chunk of memory with whatever the scripter
wanted.
Most C standard library functions for stuff like string.h were
replaced with hand-built versions to operate identically
regardless of size_t limits, because of this limitation.
Default malloc wrapper now checks to see if allocation size is
over ~(size_t)0 bytes.
34. PowerPC (Linux) specific
32-bit structs get packed differently from 32-bit ints in arguments
on whatever calling convention was the default for GCC.
Passed a structure containing a single uint32 in a varags field
that turned it into a 32-bit uint on the other side. Stack
corruption. (Function was for debug output.)
35. Everywhere
SIGFPE without dividing by zero.
Integer division instruction protected from divide-by-zero.
Still got SIGFPE through AFL run.
-2147483648 / -1 = +2147483648
+2147483648 is outside of 32-bit signed twos complement integer.
SIGFPE generated when the resulting value can’t expressed in the
output range.
Actually ran into this one twice - runtime and optimizer had
the same bug.
36. Everywhere (cont.)
AFL discovered lots of places where a buffer size in the
deserializer could be specified as 0xffffffff. 0xffffffff +
allocation header = truncated tiny allocation.
AFL discovered many instances where allocation count * object size
were > max size_t.
Wrote an array allocator/reallocator wrapper that checks for
overflow.
37. Lessons learned
AFL is amazing. Always use AFL.
Valgrind too.
If you really want to prevent all integer overflows, you have a lot
of checking to do.
Ninkasi has overflow checks everywhere.
38. Future Work
39. Faster hash tables
Current hash tables are "buckets with linked lists".
Terrible for cache locality.
Flat array with quadratic probing would be better.
Tradeoff of performance vs simplicity.
40. PUSHLITERAL_INT is like 1/4 to 1/2 of my generated instructions
Many instructions take two parameters with one immediate.
Wasting cycles just to get the immediate value onto the stack before
immediately being used.
Will mean extra instructions - more complicated instruction set.
Tradeoff of performance vs simplicity, again.
41. Documentation’s not great
Finish incomplete documentation.
Example program.
Complete example library.
Custom types.
Garbage collection handling.
Error recovery.
I’ve probably put more into this presentation than all of the
documentation combined.
42. Add postfix increment/decrement
Some minor extra stack juggling.
Optimizer should be able to turn postincrement/postdecrement into
preincrement/predecrement if return value is unused.
43. Remove the previously-mentioned anti-feature
foo.bar(x) becomes foo.bar(foo, x) internally.
I have better ideas about how to handle this.
This will be the first thing I fix next time I touch the project.
44. “Closures” handled in a mediocre way
Make an object (“ob”) with _exec and _data fields, and when you call
it like a function, it turns into ob._exec(_data).
The names are given special meaning.
This is a temporary stand-in for a real solution.
45. Variadic functions
Add functions that take variable argument counts.
C callback functions can do this.
Functions written in the language itself cannot at the moment.
46. Inline function compilation
Right now it literally just inserts the function code right there
with a big JMP at the start to skip over it during normal execution
of the parent function.
This is in-elegant, but it works for now.
47. Type queries
Should be able to see if an object is a given type.
We can trivially implement this in C callbacks for basic types, but
external types need a little bit of API work.
48. An actual standard library
Because I’m tired of implementing a new version of print() with
every new project.
rand(), sin(x), cos(x), abs(x), array(...) (inline array
initialization), int(x), float(x) all had to be implemented for a
game project. These should be built-in.
Even len(x) used to be like this.
That’s all!
Gruedorf
Also, I'm counting this as my official first
Gruedorf entry.
It's a bit coincidental, because I didn't realize it had been going
until right before I decided to publish it (and also, hopefully, have
it be the start of me blogging regularly again).